Beyond Vendor Outages: Designing Systems That Survive Regional Cloud Failure
by Gary Worthington, More Than Monkeys
This article is a follow-up to my October piece: When the Cloud Goes Dark: How to Survive a Major Cloud Vendor Outage.

Last October I wrote about how cloud vendors occasionally suffer major outages and why systems should be designed to tolerate them.
The core message was simple.
Cloud providers are incredibly reliable, but they are not infallible. If your architecture assumes a region will always exist, you have built yourself a single point of failure.
Recent global events have reinforced that lesson in a slightly different way.
Because sometimes the problem is not the vendor.
Sometimes the problem is the region itself.
Cloud infrastructure may feel abstract when we are provisioning databases or deploying containers, but underneath that abstraction the infrastructure is still physical.
Servers sit in buildings.
Buildings sit in cities.
Cities sit inside countries.
And occasionally those realities collide with our architecture diagrams.
When that happens, the question becomes very practical.
What happens if an entire cloud region disappears?
Designing systems that can survive that scenario requires deliberate architectural choices that balance resilience, performance, complexity, and cost.
Availability Zones Are the Baseline, Not the Solution
Most production systems run across multiple Availability Zones.
That is good practice and should be considered the baseline for resilient infrastructure.
An Availability Zone typically consists of one or more physically separate data centres with independent power, networking, and cooling systems.
Running across multiple zones protects against many common failures:
- hardware faults
- localised power outages
- cooling failures
- networking disruptions
- maintenance incidents
But there is a subtle misunderstanding that appears frequently in architecture discussions.
Whilst Availability Zones protect against facility failure, they do not protect against regional failure.
All zones within a region still depend on shared external infrastructure such as networking backbones, power grids, and regional routing systems.
If something affects the entire region, every zone may be impacted simultaneously.
When that happens, a beautifully designed multi-AZ architecture does not help.
The region itself is gone.
Single Region vs Multi-Region Architecture
Architecture discussions often sound abstract until you visualise them. The difference between surviving a regional failure and suffering a full outage usually comes down to a handful of architectural decisions.
Single Region Deployment

In this architecture the system can survive instance failures and availability zone outages, but the entire platform still depends on a single region.
If that region becomes unavailable, the application disappears with it.
Multi-Region Deployment
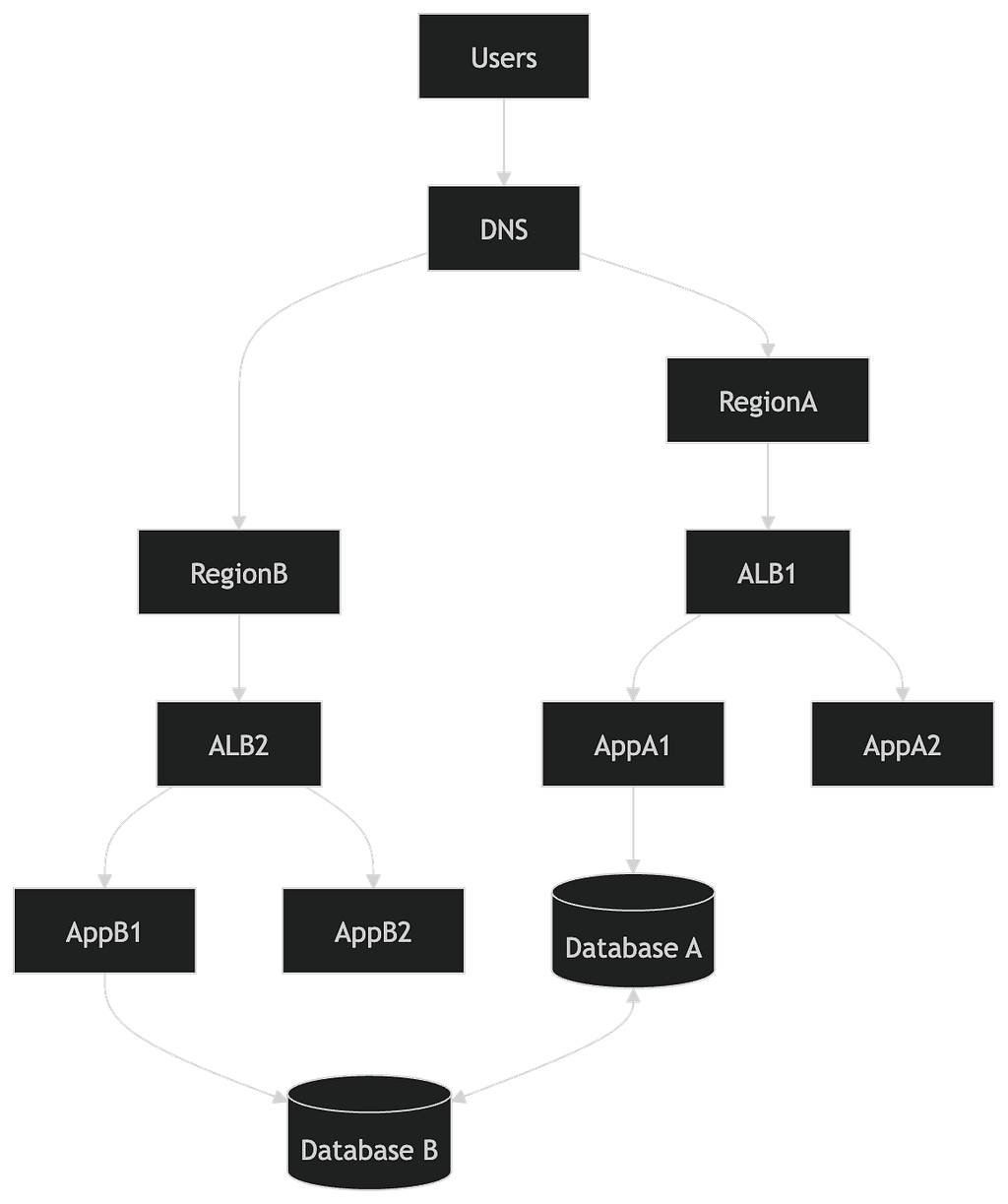
A multi-region architecture removes the region as a single point of failure.
Traffic can be redirected between regions while data replication keeps the system synchronised.
Multi-Region Architecture Patterns
Once multiple regions are introduced, the next decision is how traffic flows between them.
Two patterns appear most commonly.
Active–Passive
One region handles production traffic while another sits in standby.
Infrastructure in the standby region may run at reduced capacity until failover occurs.
Advantages:
- lower infrastructure cost
- simpler operational model
- easier database consistency
Trade-offs:
- failover takes time
- standby infrastructure must scale during recovery
For many SaaS systems this approach strikes a sensible balance between resilience and cost.
Active–Active
In an active–active architecture multiple regions serve traffic simultaneously.
Users are typically routed to the nearest region.
Advantages:
- near-instant failover
- improved global performance
- continuous validation that both regions are operational
Trade-offs:
- increased architectural complexity
- harder data consistency problems
- higher infrastructure costs
This approach is common for global consumer platforms but unnecessary for many internal systems.
The Hard Part: Data Replication
Compute infrastructure is easy to replicate.
Containers, serverless functions, and application services can be redeployed quickly in another region.
Data is much harder.
Once multiple regions are involved, the architecture must answer several questions:
- where writes occur
- how quickly updates replicate
- how conflicts are resolved
- how much data loss is acceptable
Different database technologies approach these problems differently.
Two common AWS approaches are DynamoDB Global Tables and cross-region replication in RDS.
Multi-Region Data with DynamoDB Global Tables
DynamoDB provides one of the simplest multi-region data architectures through Global Tables.
Global Tables replicate data automatically between multiple regions and allow applications to read and write from any region.

Each region hosts its own replica table. DynamoDB synchronises changes between them automatically.
Replication usually completes within seconds.
This architecture enables active-active database deployments, where applications can read and write from multiple regions simultaneously.
However, there are some trade-offs.
Conflict resolution follows a last-writer-wins model, which works well for many workloads but requires careful design for systems where simultaneous updates are common.
Replication is also eventually consistent across regions. Reads may briefly return slightly older data.
For most applications this delay is perfectly acceptable.
Multi-Region Strategies for AWS RDS
Relational databases require a different approach.
Most relational systems are not designed for active-active replication across regions.
AWS therefore provides several patterns.
Cross-Region Read Replicas

The primary database handles writes while replicas in other regions receive updates asynchronously.
Advantages include:
- simple architecture
- minimal application changes
- relatively low cost
The main trade-off is replication lag.
If the primary region fails before replication completes, some recent data may be lost.
For most systems the risk is small because replication lag is typically measured in seconds.
Multi-AZ Plus Cross-Region Replication
A more resilient architecture combines zone-level and regional redundancy.
Region A hosts the primary database with Multi-AZ failover protection.
Region B hosts a cross-region replica.
This architecture protects against:
- instance failure
- availability zone failure
- regional failure
Failover procedures can be automated or triggered manually depending on operational requirements.
Aurora Global Database
For organisations using Aurora, AWS provides Aurora Global Database.
This replicates storage across regions with significantly lower latency than traditional cross-region replication.
Failover times are faster, although the architecture becomes more tightly coupled to the Aurora ecosystem.
Traffic Routing and Failover
Replicated infrastructure is only useful if traffic can be redirected during failures.
Most architectures achieve this through DNS-based routing.

Services such as Route53 monitor the health of each region.
If a region fails health checks, traffic is automatically redirected to another region.
DNS failover is not instantaneous due to caching behaviour, but it is usually fast enough for most systems.
More advanced architectures use global load balancers or edge networks to accelerate failover further.
The key point is simple.
Failover should be automated.
No one wants to be editing DNS records manually at three in the morning.
Resilience Must Be Cost-Aware
Multi-region infrastructure can easily double cloud costs if implemented without discipline.
The solution is not to replicate everything.
It is to prioritise.
A practical architecture might look like this:
SystemResilience StrategyPaymentsactive multi-regionCore APIsactive-passiveAnalyticssingle regionDevelopment environmentssingle region
Critical systems receive the highest resilience.
Lower priority workloads accept some downtime.
This approach balances reliability with financial reality.
The Question Most Teams Avoid
The cloud industry has done an excellent job of abstracting infrastructure away from the real world.
We think in terms of regions, zones, and services.
But underneath that abstraction are still very ordinary things.
Buildings.
Power grids.
Network cables.
Human operators.
Those things fail.
Sometimes because of software bugs, Sometimes because of configuration mistakes.
And sometimes because the real world intrudes in ways architecture diagrams rarely consider.
The question for engineering teams is not whether those failures will happen. The question is whether your system assumes they never will.
Because the difference between a brief incident and a full platform outage is often a single architectural decision made months or years earlier.
And those decisions only matter on the day everything stops working.
Gary Worthington is a software engineer, delivery consultant, and fractional CTO who helps teams move fast, learn faster, and scale when it matters. He writes about modern engineering, product thinking, and helping teams ship things that matter.
Through his consultancy, More Than Monkeys, Gary helps startups and scaleups improve how they build software — from tech strategy and agile delivery to product validation and team development.
Visit morethanmonkeys.co.uk to learn how we can help you build better, faster.
Follow Gary on LinkedIn for practical insights into engineering leadership, agile delivery, and team performance.